%20(1).jpg)
There is a moment, familiar to anyone who has ever tried to decode their own benefits package, where the eyes glaze over, and the spirit quietly leaves the body. You have the PDF open. You have three browser tabs competing for your attention. You might even ask an AI chatbot for help. And the chatbot, articulate and confident, tells you that most employers match up to 6% of your salary.
Lovely. But what does your employer match?
This is the gap we set out to close.
We built an MCP server that connects AI to real, personalized employee benefits data.

The models are extraordinary reasoners. They can parse tax law, explain insurance terminology, and walk you through the mechanics of a high-deductible health plan with the patience of a saint. What they cannot do is accurately tell you how much your employer contributes to your 401(k) or whether your doctor is in your currently enrolled network.
Employee benefits sit at the intersection of everything AI struggles with: deep personalization, tenant-specific configuration, sensitive data, and byzantine nested structures that differ from company to company. Every employer assembles their plans differently. Every employee's elections reflect a unique set of circumstances. The data is yours and yours alone.
MCP, the Model Context Protocol, Anthropic's open standard for connecting AI to external tools and data, gave us the abstraction we needed. The metaphor that stuck with our team was simple: MCP is a USB port. Any compatible server exposes its capabilities. The handshake is standardized without compromising the possibilities.
Build one MCP server, and suddenly, Claude Desktop or Cursor can check your enrolled benefits or your specialist copay while you're writing code. Any future MCP-compatible client gets instant access, no bespoke integration required.
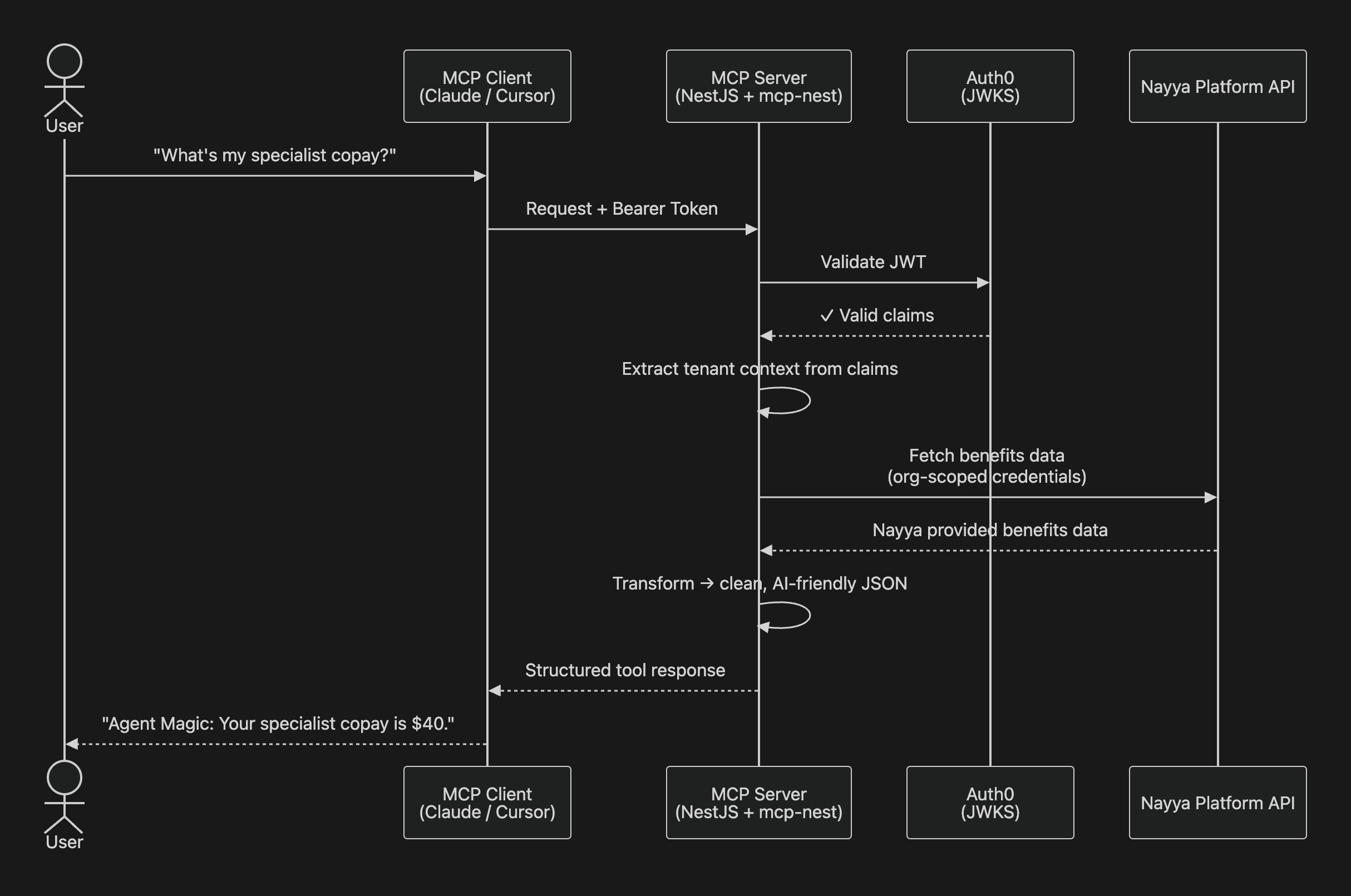
When a user asks Claude something like "What's my specialist copay?", here is what actually happens.
The request arrives at our MCP server, a NestJS application used to handle the protocol machinery carrying a Bearer token for a fully authenticated user. That token gets validated against Auth0 via JWKS. Inside the JWT live the required claims. They tell the server whose data to fetch without the user ever needing to identify themselves explicitly.
From there, the server calls our platform API with the appropriate credentials, retrieves the benefits data, transforms it from its deeply nested native structure into clean, AI-friendly JSON, and returns it. The AI reasons over the data and gives the user a clear, human answer.
Our stack is NestJS for the framework, Auth0 for identity, HTTP and SSE for web transport (with STDIO for desktop clients like Cursor), Datadog for observability, and Docker on EKS for deployment. Nothing exotic. The discipline is in the design, not the tooling.
If you've ever dreaded the idea of implementing a new protocol, we have good news. Writing an MCP tool is almost anticlimactic. A decorator. A Zod schema. An async function. The framework handles the protocol. You handle the logic.
We shipped a set of custom tools, each mapped to a question real employees actually ask:
"What health plans can I choose from?"
"Does my employer put money in my HSA?”: returning exact dollar amounts.
"What's my 401k match?"
"How much is a specialist visit?"
"What am I enrolled in?"
If writing the tools was easy, everything surrounding them was not. A few challenges consumed the majority of our engineering hours, and they are worth understanding.
Combining organization-scoped and user-scoped authorization is a big challenge. Company A's employees must never see Company B's plans; additionally, within the same Company A, Employee A must not be allowed to see data for Employee B. Each organization has a unique set of permissions allowing it access to its own data and users. The JWT's claims indicate the organization and user for which the MCP is being invoked, and we exchange the MCP for an API token for the same user in the same organization. NestJS's request-scoped services kept this clean, but the coordination required careful thought.
Benefits data, in its raw form, is a nightmare. This is not hyperbole. Benefits data is often unstructured and nested 5 levels deep. So we transform it within our platform to our homegrown BenefitsIQ schema. Our service layer flattens the labyrinth into clean, legible JSON. Family roles become human-readable coverage types. Copay amounts become dollar figures. Contribution rules become plain statements. By the time the AI sees the data, it looks like something a thoughtful human would have written by hand.
Rather than wrestling with raw, inconsistent data from multiple sources, Nayya’s BenefitIQ had already standardized benefits information into a consistent schema. This meant the MCP server could rely on predictable field names, data types, and hierarchies instead of handling dozens of employer-specific formats.
The schemas encoded domain knowledge about benefits, understanding that a "family" coverage tier means something specific, that HSA contributions have distinct employer and employee components, or that copays vary by service type. This semantic layer made the transformation from nested structures to AI-friendly JSON much more straightforward, because the meaning was already captured in the schema rather than buried in arbitrary field names.
Since BenefitIQ was designed for multi-tenant benefits administration, the schemas naturally supported the kind of organization-scoped queries your MCP server needed. Each tenant's data was already properly isolated and queryable, which aligned perfectly with our JWT-based authentication model.
MCP infrastructure could be the future of integrations.
We built a production server that connects any MCP-compatible client to real benefits data, handles enterprise-grade multi-tenant authentication with token exchange, transforms deeply complex data into structures AI can reason about, and deploys to Kubernetes with full observability. The protocol layer was built once. Every AI client that speaks MCP gets access.
The hardest part was not the AI. It was not the protocol. It was making the data legible, and that's precisely where Nayya's comprehensive employee data platform solved the problem. Our platform had already done the hard work of structuring, normalizing, and organizing benefits data across tenants. MCP simply gave us the protocol to expose it.
*For those inclined to dig deeper:
the MCP specification
Auth0's Custom Token Exchange documentationMCP is a USB port, not a hard drive
